Blog du SSP Lab

Le plongement lexical, ou comment apprendre à lire à un ordinateur
Lucas Malherbe | 11 juillet 2022
Les données textuelles constituent une source extraordinaire d’informations, que ce soit sous la forme d’e-mails, de réponses à des enquêtes ou encore de commentaires sur les réseaux sociaux. À l’I
Suite →
Sur les bonnes pratiques de code avec Python
Tom Seimandi | 20 avril 2022
Post en cours de rédaction.
Écrire du code de bonne qualité est indispensable lorsqu'on souhaite développer des applications pérennes qui dépassent un certain niveau de complexité. Pour
Suite →Le Machine Learning aux Journées de la Méthodologie Statistique (JMS)
Aurélien | 6 avril 2022
Signes des temps, l'édition 2022 des Journées de la Méthodologie Statistique a mis en lumière la part croissante du Machine Learning dans les travaux menés au sein de la Statistique Publique, et
Suite →
Introduction à l'économétrie en grande dimension et à la sélection de variables
Jérémy L'Hour | 22 octobre 2020
Vous voulez en savoir plus sur l'économétrie en grande dimension et la sélection de variable? Ce billet est fait pour vous.
Les situations de "grande dimension", c'est-à-dire lorsque l'on
Suite →
Données groupées : effets aléatoires vs effets fixes
SSP Lab | 25 juin 2017
Le choix entre effets fixes et effets aléatoires est un grand classique de la microéconométrie, qu’on rencontre en particulier lorsqu’on dispose de données de panel, ou plus généralement lorsqu’on dis
Suite →
Exploration des données avec Gephi
Robert Pastorelli | 17 novembre 2016
On a vu dans l’article précédent qu’il pouvait parfois être intéressant de considérer la dimension « réseau » des données (flux, interactions, échanges, relations entre entités…). Parmi les outils lib
Suite →
Données en réseau
Robert Pastorelli | 26 octobre 2016
Certaines données peuvent être analysées sous forme de réseaux, c’est-à-dire que l’on s’intéresse aux relations entre des entités. Ainsi, des entités quelconques (personnes, organismes, objets, l
Suite →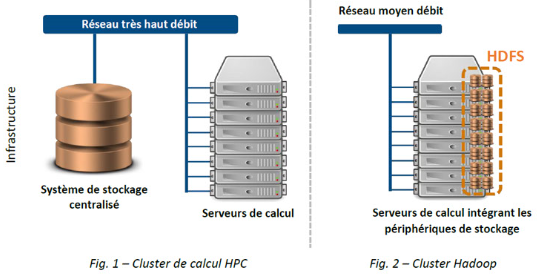
Clusters Big Data VS clusters de calcul, quelle différence ?
Romain et Stéphanie | 8 juin 2016
Le traitement des données massives est avant tout un enjeu technique. Avant même d’envisager une exploration de données massives pour extraire de l’information, il faut être en mesure de stocker
Suite →
Parallélisation des traitements : Hadoop MapReduce vs Spark
Romain et Stéphanie | 8 juin 2016
À la base des systèmes dits « big data », il y a un principe central : la distribution, à la fois des données et des traitements, sur un ensemble de machines/ordinateurs formant un cluster. Le sto
Suite →A propos de ce blog
Les informations qui y sont diffusées n'engagent que les contributeurs et en aucun cas les institutions dont ils dépendent.