
Le plongement lexical, ou comment apprendre à lire à un ordinateur
11 juillet 2022
Les données textuelles constituent une source extraordinaire d’informations, que ce soit sous la forme d’e-mails, de réponses à des enquêtes ou encore de commentaires sur les réseaux sociaux. À l’Insee par exemple, une problématique récurrente est de classer des libellés (professions, noms de produits, etc.) dans des nomenclatures. Mais il existe une difficulté avec ce type de données : le langage naturel n'a pas de sens pour un ordinateur. Un algorithme ne travaille qu'avec des nombres. Il faut donc d'abord transformer l'information pour la rendre compréhensible par une machine. Il existe principalement deux approches pour cela :
- le bag of words (sac de mots),
- et le plongement lexical.
Approche bag of words
La manière la plus simple de transformer des phrases ou des libellés textuels en une information numérique est de passer par un objet que l’on appelle la matrice document-terme. L’idée est de compter les mots (les termes) présents dans chaque phrase ou libellé (le document). Considérons un corpus constitué des trois phrases suivantes :
- La pratique du tricot et du crochet
- Transmettre la passion du timbre
- Vivre de sa passion
La matrice document-terme associée à ce corpus est la suivante :
| crochet | de | du | et | la | passion | pratique | sa | timbre | transmettre | tricot | vivre | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| La pratique du tricot et du crochet | 1 | 0 | 2 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| Transmettre sa passion du timbre | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| Vivre de sa passion | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
Mission accomplie ! Chaque phrase du corpus est associée à un vecteur numérique. Il est maintenant possible de manipuler cette matrice comme des données tabulaires classiques. Par exemple, pour classer ces phrases dans des catégories, on pourrait appliquer l’un des algorithmes usuels de machine learning pour les tâches de classification (régression logistique, forêt aléatoire, gradient boosting, etc.). Cependant, même si cette représentation via la matrice document-terme répond au besoin initial de transformer les données, un autre type de représentation se place souvent comme une meilleure option : le plongement lexical.
Le principe du plongement lexical
Le plongement lexical (word embedding en anglais) consiste à représenter chaque mot par un vecteur de taille fixe, de façon à ce que deux mots dont le sens est proche possèdent des représentations numériques proches. Ainsi les mots « chat » et « chaton » devraient avoir des vecteurs de plongement assez similaires, eux-mêmes également assez proches de celui du mot « chien » et plus éloignés de la représentation du mot « maison ».
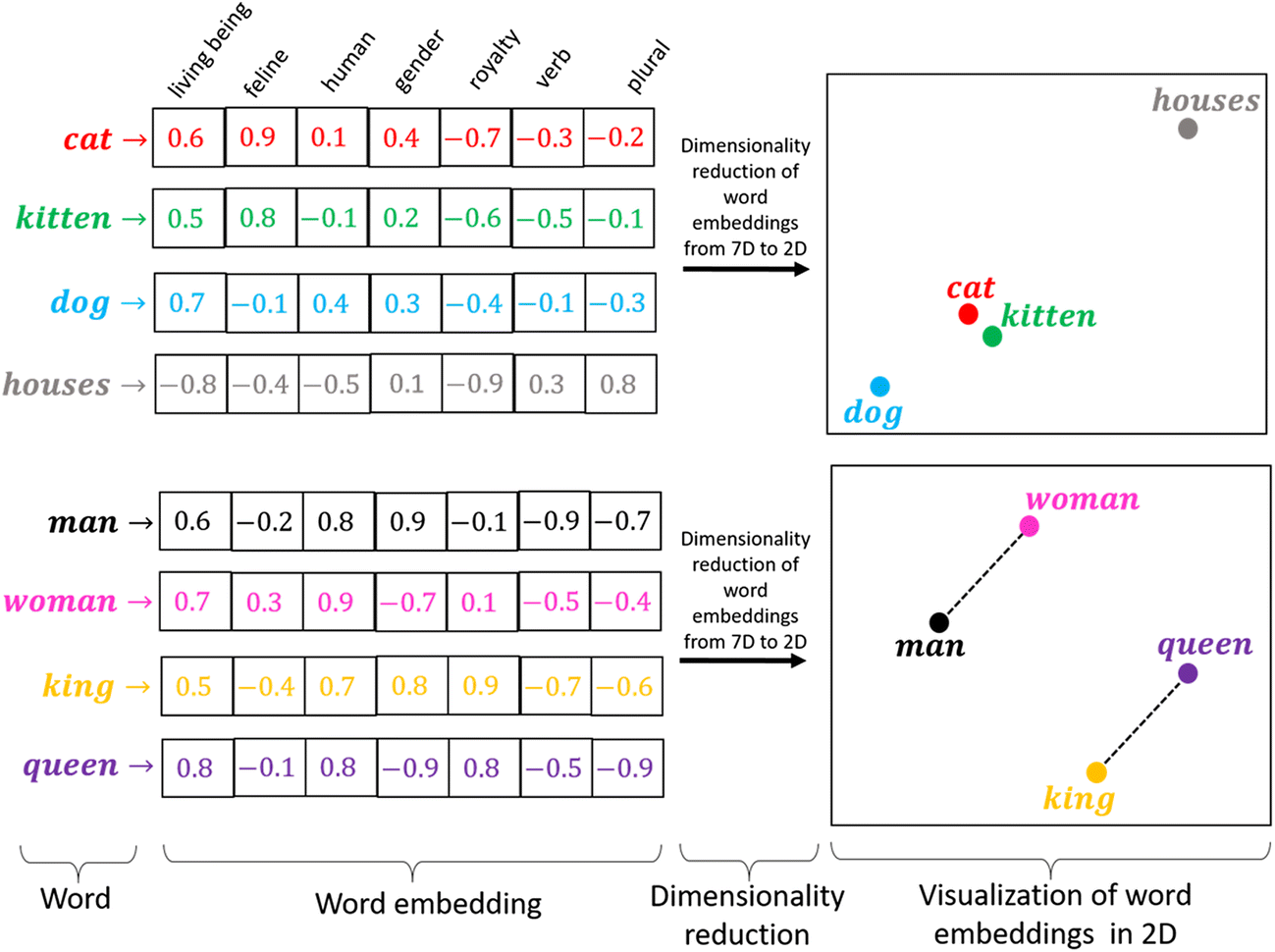
Chaque composante va encoder des informations différentes, comme le fait d’être un être vivant, le genre, l’âge, le niveau d’abstraction, etc.. En pratique, les vecteurs de plongements ont quelques dizaines voire quelques centaines de composantes et il est impossible d’associer à chacune un concept clair : toutes les notions s’entremêlent, mais chaque composante à un rôle à jouer.
Le plongement lexical possède deux avantages par rapport à l’approche bag of words :
- Il fournit une représentation dense, plus adaptée aux algorithmes d’apprentissage statistique que la matrice creuse (contenant beaucoup de zéros) de l’approche bag of words ;
- Les opérations mathématiques ont un sens sur les vecteurs du plongement.
Il devient en effet possible de faire des mathématiques avec les mots. Ainsi par exemple, les vecteurs résultant de la différence entre les représentations des mots « femme » et « homme » d’une part, et des mots « reine » et « roi » d’autre part, devraient être proches, car conceptuellement ces couples de mots sont régis par la même relation : un changement de genre.
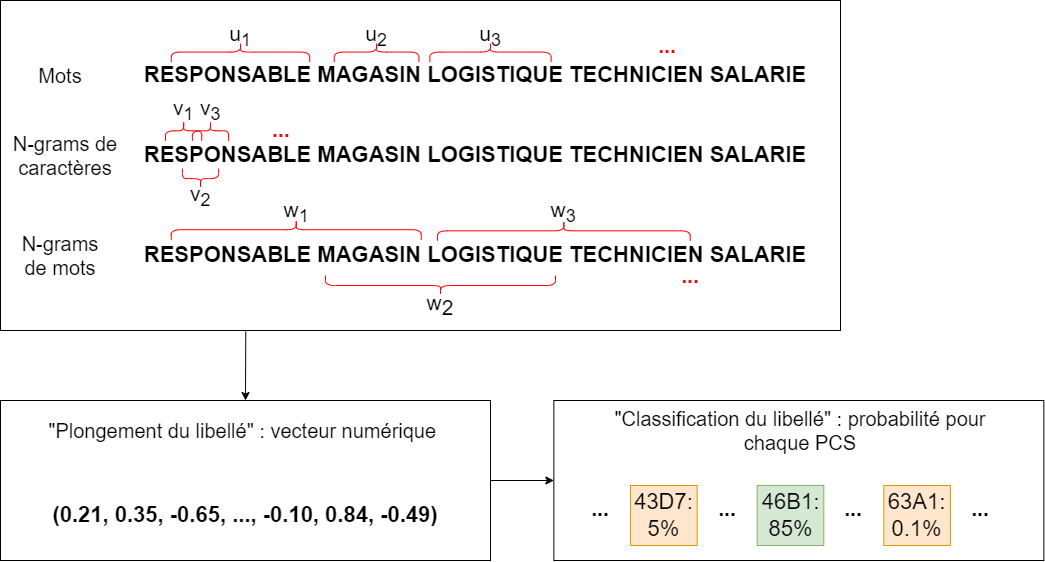
Jusqu’ici, nous avons parlé du plongement de mots, mais comment obtenir le plongement d’un libellé textuel ? Une possibilité est de considérer tous les mots qui composent le libellé et de calculer la moyenne de leurs vecteurs de plongement.
Construction d’un plongement lexical
Un plongement lexical se construit en parcourant un grand corpus de textes (l’ensemble des articles Wikipedia par exemple) et en repérant les mots qui apparaissent souvent dans le même contexte. Le contexte d’un mot est défini par une fenêtre de taille fixe autour de ce mot. La taille de la fenêtre est un paramètre de la construction de l’embedding. Le corpus fournit un grand ensemble d’exemples mots-contexte, qui peuvent servir à entraîner un réseau de neurones.
Plus précisément, il existe deux approches :
- Continuous bag of words (CBOW), où le modèle est entraîné à prédire un mot à partir de son contexte ;
- Skip-gram, où le modèle tente de prédire le contexte à partir d’un seul mot.

Algorithmes open source
La méthode de construction d’un plongement lexical présentée ci-dessus est celle de l’algorithme word2vec. Il s’agit d’un modèle open source développé par une équipe de Google en 2013. word2vec a été le pionnier en termes de modèles de plongement lexical, mais d’autres algorithmes existent.
Le modèle GloVe constitue un autre exemple. Développé en 2014 à Stanford, ce modèle ne repose pas sur des réseaux de neurones mais sur la construction d’une grande matrice de co-occurrences de mots. Pour chaque mot, il s’agit de calculer les fréquences d’apparitions des autres mots dans une fenêtre de taille fixe autour de lui. La matrice de co-occurrences obtenue est ensuite factorisée par une décomposition en valeurs singulières.
A l’Insee, plusieurs modèles de classification de libellés textuels dans des nomenclatures reposent sur l’algorithme de plongement lexical fastText. Développé en 2016 par une équipe de Facebook, fastText fonctionne de façon similaire à word2vec mais se distingue particulièrement sur deux points :
- En plus des mots eux-mêmes, le modèle apprend des représentations pour les n-grammes de mots (sous-séquences de caractères de taille \(n\), par exemple « tar », « art » et « rte » sont les trigrammes du mot « tarte »), ce qui le rend notamment robuste aux variations d’orthographe ;
- Le modèle a été optimisé pour que son entraînement soit particulièrement rapide.
Comment utiliser ces modèles en pratique ? En Python, le package gensim met en œuvre les modèles word2vec et fastText. Chacun des trois modèles présentés ici possède également son package dédié. En R, il faut utiliser les packages word2vec, text2vec (pour le modèle GloVe) et fastTextR.
Bonus : le plongement lexical en version ludique
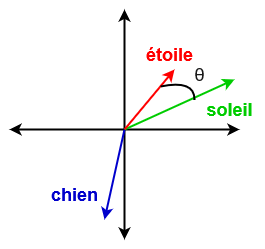
Le résultat d’un plongement lexical peut avoir de nombreux usages. Par exemple, il rend possible le calcul de la proximité entre deux mots quelconques. Une manière de procéder est de calculer la similarité cosinus entre les vecteurs de plongement des deux mots. Plus précisément, la similarité entre deux mots de représentations vectorielles \(u\) et \(v\) est définie comme le cosinus de leur angle \( \theta \) : $$cos(\theta) = \frac{u \cdot v}{\left\|u\right\| \left\|v\right\|} $$
Le calcul de la proximité entre les mots est à la base du jeu cemantix. Le principe : il y a un mot à trouver chaque jour, il s’agit de faire des propositions de mots et le jeu répond en donnant la proximité entre les mots proposés et le mot du jour. Ainsi, au fil des propositions, on a une vision de plus en plus précise du champ lexical associé au mot mystère, jusqu’à finalement le trouver.
A propos de ce blog
Les informations qui y sont diffusées n'engagent que les contributeurs et en aucun cas les institutions dont ils dépendent.