Clusters Big Data VS clusters de calcul, quelle différence ?
8 juin 2016
Le traitement des données massives est avant tout un enjeu technique. Avant même d’envisager une exploration de données massives pour extraire de l’information, il faut être en mesure de stocker ces données et d’effectuer dessus des traitements en un temps raisonnable. Pour ce faire, des environnements logiciels adaptés ont été développés depuis une quinzaine d’années par et pour les entreprises manipulant des bases de données gigantesques. Il existe aujourd’hui tout un panorama de solutions, le plus souvent open-source, pour le traitement de ces volumes. Les performances de systèmes comme Hadoop ou MapReduce voire Spark font aujourd’hui consensus, mais que se cache-t-il derrière ces noms ? Quelle différence avec les solutions historiques (supercalculateurs, clusters de calcul HPC)?
À la base des systèmes dits « big data », il y a un principe central : la distribution, à la fois des données et des traitements, sur un ensemble de machines/ordinateurs formant un cluster. Le stockage des données brutes s’appuie le plus souvent sur un système de fichiers distribués. Dans les faits, les fichiers sont donc découpés en blocs de taille constante, répartis et répliqués de manière homogène sur l’ensemble des machines dédiées au stockage.
– Cette répartition va permettre le traitement en parallèle des données et donc un gain de temps proportionnel au nombre de machines utilisées. Dans la pratique, le développeur conçoit son programme puis le transmet au logiciel supervisant le cluster qui aura la charge de le transmettre à son tour aux différents nœuds de traitement mais également de s’assurer du bon déroulement des opérations. En effectuant les opérations directement au niveau des nœuds on gagne le temps de déplacement des données.

– La réplication permet en outre une tolérance à la panne d’une ou plusieurs machines, d’autant plus probable que le nombre de machines est grand. Les architectures « big data » sont donc conçues pour être robustes.
Ce principe est flexible puisqu’en cas d’accroissement sensible des données, il suffit de rajouter des machines, ni l’architecture informatique dans sa globalité ni les traitements ne doivent être refondus : on dit que le système passe à l’échelle. Hadoop est la solution historique de stockage (avec HDFS) et de traitement (MapReduce) des big data. Plus récemment est apparu un nouveau challenger, Spark, qui est devenu la solution de référence pour le traitement de données massives.
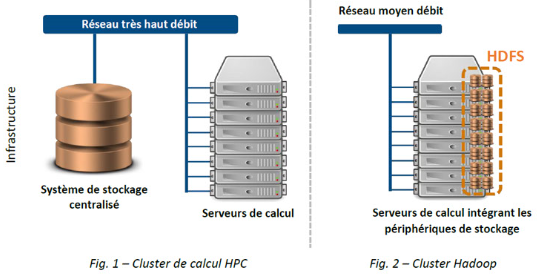
Cette technologie ne doit pas être confondue avec la parallélisation d’un calcul sur les cœurs d’un micro-processeur par exemple, au sens où dans ce dernier cas chacun des nœuds impliqués dans le calcul a accès à l’intégralité des données et c’est le calcul seul qui est distribué entre différentes unités de calcul (par exemple différentes itérations d’un même algorithme). Dans le cas où l’on met en commun la capacité de calcul d’un grand nombre de machines, on parle de cluster de calcul ou HPC (High Performance Computing, calcul haute performance). Cette technologie, plus ancienne (apparu dans les années 60 et popularisée dans les années 90), est caractérisée par un grand nombre de serveurs dont les processeurs sont mobilisés pour effectuer les calculs des utilisateurs (calculs pouvant être très complexes), un système de stockage de données centralisé permettant la sollicitation simultanée par de nombreux serveurs de calcul et un réseau très haut débit reliant les serveurs entre eux ainsi qu’au système de stockage central.

Le choix entre ces deux architectures repose sur des compromis : ainsi si l’on souhaite appliquer des traitements relativement simples ou parallélisable sur un énorme volume de données, il sera moins coûteux de laisser les données en place et d’aller effectuer le traitement localement (les fichiers distribués sur des machines distinctes avec leurs propres capacités de calcul), pour ne déplacer vers le serveur maître qu’un résultat agrégé plutôt que faire transiter cette énorme quantité de données vers les serveurs de calcul (ce qui entraînerait d’importants coûts en termes d’infrastructures de réseaux). A l’inverse, si les données ne sont pas suffisamment importantes, ou que les traitements sont beaucoup plus sophistiqués, les coûts fixes d’une architecture Big Data pourrait la rendre moins attrayante.
Romain & Stéphanie
A propos de ce blog
Les informations qui y sont diffusées n'engagent que les contributeurs et en aucun cas les institutions dont ils dépendent.